

1
1.1 MODELOS DE BASES DE DATOS
Un
modelo de datos es básicamente una "descripción" de algo conocido
como contenedor de datos (algo en donde se guarda la información), así como de
los métodos para almacenar y recuperar información de esos contenedores. Los
modelos de datos no son cosas físicas: son abstracciones que permiten la
implementación de un sistema eficiente de base de datos; por lo general se
refieren a algoritmos, y conceptos matemáticos.
Algunos
modelos con frecuencia utilizados en las bases de datos:

En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las
bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones
que manejan un gran volumen de información y datos muy compartidos permitiendo
crear estructuras estables y de gran rendimiento.
Una
de las principales limitaciones de este modelo es su incapacidad de representar
eficientemente la redundancia de datos.
Base de datos
de red:

Éste es un modelo ligeramente distinto del
jerárquico; su diferencia fundamental es la modificación del concepto de nodo:
se permite que un mismo nodo tenga varios padres (posibilidad no permitida en
el modelo jerárquico).
Fue
una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución
eficiente al problema de redundancia de datos; pero, aun así, la dificultad que
significa administrar la información en una base de datos de red ha significado
que sea un modelo utilizado en su mayoría por programadores más que por
usuarios finales.
Son
bases de datos cuyo único fin es el envío y recepción de datos a grandes
velocidades, estas bases son muy poco comunes y están dirigidas por lo general
al entorno de análisis de calidad, datos de producción e industrial, es
importante entender que su fin único es recolectar y recuperar los datos a la
mayor velocidad posible, por lo tanto la redundancia y duplicación de
información no es un problema como con las demás bases de datos, por lo general
para poderlas aprovechar al máximo permiten algún tipo de conectividad a bases
de datos relacional.
Bases de datos relacionales
{kind=link}

Estés el modelo utilizado en la actualidad para modelar problemas reales y administrar datos dinámica mente. Tras ser postulados sus fundamentos en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de "relaciones". Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que ésta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En
este modelo, el lugar y la forma en que se almacenen los datos no tienen
relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto
tiene la considerable ventaja de que es más fácil de entender y de utilizar
para un usuario esporádico de la base de datos. La información puede ser
recuperada o almacenada mediante "consultas" que ofrecen una amplia
flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las
consultas a bases de datos relacionales es SQL, Structured Query Language o
Lenguaje Estructurado de Consultas, un estándar implementado por los
principales motores o sistemas de gestión de bases de datos relacionales.
1.2 CONSIDERACIONES DE DISEÑO

Una Base de Datos sirve para guardar datos en ella y para procesar dichos datos. El resultado de ese proceso se llama INFORMACIÓN.
DATOS
—> PROCESO —> INFORMACIÓN
Los usuarios ingresan los DATOS en las tablas, en los stored procederes y en los triggers se PROCESAN esos datos, y el resultado de ese procesamiento es la INFORMACIÓN que se obtiene.
Para
que la INFORMACIÓN sirva debe ser exacta, oportuna y confiable. Esto solamente
puede conseguirse si los DATOS introducidos son exactos y si el PROCESO al que
son sometidos es correcto. Si cualquiera de ellos (datos o proceso) está mal
entonces es seguro que la INFORMACIÓN estará mal.
La
introducción de los DATOS corre por cuenta y es responsabilidad de los
usuarios.
El
PROCESAMIENTO y la INFORMACIÓN corren por cuenta y es responsabilidad del
diseñador de la Base de Datos.
Si
un DATO es incorrecto, fue mal introducido, parte de la culpa puede ser del
usuario y la otra parte de la culpa puede ser del diseñador de la Base de
Datos.
Para
evitar o al menos disminuir grandemente la posibilidad de que un usuario
introduzca datos erróneos el Firebird nos provee de varias herramientas:
restricción Foreign Key, restricción Ónique Key, restricción Check, dominios,
triggers.
Mediante
la restricción Foreign Key nos aseguramos que en una columna solamente se
puedan guardar valores que existen en otra tabla. Si no existen en la otra
tabla, no se grabarán.
Mediante la restricción Unique Key nos aseguramos que en una columna no haya datos repetidos. Ni duplicados, ni triplicados, ni nada de eso. Solamente datos únicos.
Mediante
la restricción Check nos aseguramos que en una columna (o serie de columnas)
solamente se puedan introducir valores que cumplen con las condiciones
impuestas.
Mediante
los dominios nos aseguramos que los valores de una columna sean solamente los
permitidos.
Mediante
los triggers nos aseguramos que antes de insertar o actualizar una fila los
valores de sus columnas sean valores permitidos.
Si
los DATOS o el PROCESO son incorrectos entonces lo que se obtiene no sirve, en
otras palabras se obtiene basura, porque DATOS correctos utilizados por un
PROCESO incorrecto da como resultado basura y DATOS incorrectos utilizados por
un PROCESO correcto también dan por resultado basura.
Un
“dato” es lo que se guarda, una “información” es lo que se obtiene después de
“procesar” a los “datos”.
Siempre
por el final, o sea por la INFORMACIÓN que los usuarios desean obtener. Esto
implica que se debe entrevistar a los usuarios para preguntarles todo lo concerniente
a la INFORMACIÓN que necesitan.
- PRODUCTOS (Identificador, Código, Nombre, Cantidad inicial, Fecha de la cantidad inicial, etc.)
- CLIENTES (Identificador, Nombre, Dirección, Teléfono,etc.)
- VENTAS CABECERA (Identificador, Tipo de documento, Número de documento, Fecha de la venta, Identificador del cliente, etc.)
- VENTAS DETALLES (Identificador, Identificador de la cabecera, Identificador del producto, Cantidad, Precio unitario, etc.)
- COBRANZAS (Identificador, Fecha de la cobranza, Identificador del cliente, Número de Factura cobrada, Monto cobrado, etc.)
- PROVEEDORES (Identificador, Nombre, Dirección, Teléfono, etc.)
- COMPRAS CABECERA (Identificador, Tipo de documento, Número de documento, Fecha de la compra, Identificador del proveedor, etc.)
- COMPRAS DETALLES (Identificador, Identificador de la cabecera, Identificador del producto, Cantidad, Precio unitario, etc.)
- PAGOS (Identificador, Fecha del pago, Identificador del proveedor, Número de la factura pagada, Monto pagado, etc.)
Al
saber cuáles informes requieren los usuarios ya es fácil determinar cuáles
tablas se deberán crear para cumplir con ellos.
1.3 NORMALIZACIONES

Uno de los factores más importantes en la
creación de páginas web dinámicas es el
diseño de las Bases de Datos (BD). Si
tus tablas no están correctamente diseñadas,
te pueden causar un montón de
dolores de cabeza cuando tengas de realizar
complicadísimas llamadas SQL en el
código PHP para extraer los datos que necesitas.
Si conoces como establecer las relaciones
entre los datos y la normalización de
estos, estarás preparado para comenzar a
desarrollar tu aplicación en PHP.
Si trabajas con MySQL o con Oracle, debes
conocer los métodos de normalización del
diseño de las tablas en tu sistema de
BD relacional. Estos métodos pueden ayudarte a
hacer tu código PHP más fácil de
comprender, ampliar, y en determinados casos,
incluso hacer tu aplicación más
rápida.
Básicamente, las reglas de Normalización
están encaminadas a eliminar redundancias e
inconsistencias de dependencia en
el diseño de las tablas. Más tarde explicaré lo que
esto significa mientras
vemos los cinco pasos progresivos para normalizar, tienes que
tener en cuenta
que debes crear una BD funcional y eficiente.
También detallaré los tipos de relaciones que
tu estructura de datos puede tener.
Digamos que queremos crear una tabla con la
información de usuarios, y los datos a
guardar son el nombre, la empresa, la
dirección de la empresa y algún e-mail, o bien
URL si las tienen. En principio comenzarías
definiendo la estructura de una tabla como
esta.
Formalización CERO

Diríamos que la anterior tabla esta en nivel
de Formalización Cero porque ninguna de
nuestras reglas de normalización ha sido aplicada. Observa los campos url1 y url2 --¿Qué haremos cuando en nuestra aplicación necesitemos una tercera url ? ¿Quieres? Tener que añadir otro campo/columna a tu tabla y tener que reprogramar toda la entrada de datos de tu código PHP? Obviamente no, tú quieres crear un sistema funcional que pueda crecer y adaptarse fácilmente a los nuevos requisitos.
nuestras reglas de normalización ha sido aplicada. Observa los campos url1 y url2 --¿Qué haremos cuando en nuestra aplicación necesitemos una tercera url ? ¿Quieres? Tener que añadir otro campo/columna a tu tabla y tener que reprogramar toda la entrada de datos de tu código PHP? Obviamente no, tú quieres crear un sistema funcional que pueda crecer y adaptarse fácilmente a los nuevos requisitos.
Primer nivel de Formalización/Normalización. (F/N)
1. Eliminar los grupos repetitivos de las tablas individuales.
2. Crear una tabla separada por cada grupo de datos relacionados.
3. Identificar cada grupo de datos relacionados con una clave primaria.
¿Ves que estamos rompiendo la primera regla
cuando repetimos los campos url1 y url2? ¿Y qué pasa con la tercera regla, la
clave primaria? La regla tres básicamente significa que tenemos que poner un
campo tipo contador auto incrementable para cada registro. De otra forma, ¿Qué
pasaría si tuviéramos dos usuarios llamados Joe y queremos diferenciarlos. Una
vez que aplicaremos el primer nivel de F/N nos encontraríamos con la siguiente
tabla:

Ahora diremos que nuestra tabla está en el
primer nivel de F/N. Hemos el problema de la limitación del campo url. Pero sin
embargo vemos Otros problemas....Cada vez que introducimos un nuevo registró en
la tabla Usuarios, tenemos que duplicar el nombre de la empresa y del usuario.
No sólo Nuestra BD crecerá muchísimo, sino que será muy fácil que la BD se
corrompa si escribimos mal alguno de los datos redundantes. Aplicaremos pues el
segundo
Nivel de F/N:
Segundo nivel de F/N
1. Crear tablas separadas para aquellos
grupos de datos que se aplican a varios registros.
2. Relacionar estas tablas mediante una clave
externa. Hemos separado el campo url en otra tabla, de forma que podemos añadir
más en el futuro si tener que duplicar los demás datos. También vamos a usar nuestra
clave primaria para relacionar estos campos:


Vale, hemos creado tablas separadas y la
clave primaria en la tabla usuarios, userId, está relacionada ahora con la
clave externa en la tabla urls, rel UserId. Esto está mejor. ¿Pero qué ocurre
cuando queremos añadir otro empleado a la empresa ABC? ¿O 200 empleados? Ahora tenemos el nombre
de la empresa y su dirección duplicándose, otra situación que puede inducirnos
a introducir errores en nuestros datos.
Así que tendremos que aplicar el tercer nivel
de F/N:
Tercer nivel de F/N. 1.
Eliminar
aquellos campos que no dependan de la clave.
Nuestro
nombre de empresa y su dirección no tienen nada que ver con el campo userId, así
que tienen que tener su propio empresa Id:

Ahora tenemos la clave primaria emprId en la
tabla empresas relacionada con la clave externa recEmpresaId en la tabla
usuarios, y podemos añadir 200 Usuarios mientras que sólo tenemos que insertar
el nombre 'ABC' una vez. Nuestras tablas de usuarios y urls pueden crecer todo
lo que quieran sin Duplicación ni corrupción de datos. La mayoría de los
desarrolladores dicen que el tercer nivel de F/N es suficiente, que nuestro
esquema de datos puede manejar fácilmente los datos obtenidos de una cualquier
empresa en su totalidad, y en la mayoría de los casos esto será cierto.
Pero echemos un vistazo a nuestro campo urls
- ¿Ves duplicación de datos ? Esto es perfectamente aceptable si la entrada de
datos de este campo es solicitada al usuario en nuestra aplicación para que teclee
libremente su url, y por lo tanto es sólo una coincidencia que Joe y Jill teclearon
la misma url. ¿Pero qué pasa si en lugar de entrada libre de texto usáramos un
menú desplegable con 20 o incluso más urls predefinidas? Entonces tendríamos
que llevar nuestro diseño de BD al siguiente nivel de F/N, el cuarto, muchos
desarrolladores lo pasan por alto porque depende mucho de un tipo muy específico
de relación, la relación 'varios-con-varios', la cual aún no hemos encontrado
en nuestra aplicación.
Relaciones entre los Datos
Antes de definir el cuarto nivel de F/N,
veremos tres tipos de relaciones entre los datos: uno-a-uno, uno-con-varios y
varios-con-varios. Mira la tabla usuarios en el Primer Nivel de F/N del ejemplo
de arriba. Por un momento imaginamos, que ponemos el campo url en una tabla
separada, y cada vez que introducimos un registro en la tabla usuarios también
introducimos una sola fila en la tabla urls. Entonces tendríamos una relación
uno-a-uno: cada fila en la tabla usuarios tendría exactamente una fila
correspondiente en la tabla urls. Para los propósitos de nuestra aplicación no
sería útil la normalización.
Ahora mira las tablas en el ejemplo del
Segundo Nivel de F/N. Nuestras tablas permiten a un sólo usuario tener
asociadas varias urls. Esta es una relación uno con-varios, el tipo de relación
más común, y hasta que se nos presentó el dilema del Tercer Nivel de F/N. la
única clase de relación que necesitamos.
La relación varios-con-varios, sin embargo,
es ligeramente más compleja. Observa en nuestro ejemplo del Tercer Nivel de F/N
que tenemos a un usuario relacionado con varias urls. Como dijimos, vamos a
cambiar la estructura para permitir que varios usuarios estén relacionados con
varias urls y así tendremos una relación varios-con-varios. Veamos como quedarían
nuestras tablas antes de seguir con este planteamiento:
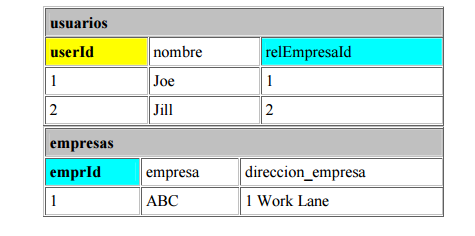

Para disminuir la duplicación de los datos (este proceso nos llevará al Cuarto Nivel de F/N), hemos creado una tabla que sólo tiene claves externas y primarias url_relations. Hemos sido capaces de remover las entradas duplicadas en la tabla urls creando la tabla url_relations. Ahora podemos expresar fielmente la relación que ambos Joe and Jill tienen entre cada uno de ellos, y entre ambos, las urls. Así que veamos exactamente que es lo que el Cuarto Nivel de F/N. supone:
Cuarto Nivel de F/N.
1.
En las
relaciones varios-con-varios, entidades independientes no pueden ser
almacenadas en la misma tabla.
Ya que sólo se aplica a las relaciones
varios-con-varios, la mayoría de los desarrolladores pueden ignorar esta regla
de forma correcta. Pero es muy útil en ciertas situaciones, tal como está.
Hemos optimizado nuestra tabla urls eliminado duplicados y hemos puesto las
relaciones en su propia tabla.
Quinto Nivel de F/N.
Existe otro nivel de normalización que se
aplica a veces, pero es de hecho algo esotérico y en la mayoría de los casos no
es necesario para obtener la mejor funcionalidad de nuestra estructura de datos
o aplicación. Su principio sugiere:
1. La tabla original debe ser reconstruida
desde las tablas resultantes en las cuales ha sido troceada.
Los beneficios de aplicar esta regla aseguran
que no has creado ninguna columna extraña en tus tablas y que la estructura de
las tablas que has creado sea del tamaño justo que tiene que ser. Es una buena
práctica aplicar este regla, pero a no ser que estés tratando con una extensa
estructura de datos probablemente no la necesitarás.
1.4
INTEGRIDAD REFERENCIAL

Al crear las relaciones entre tablas podemos elegir que se cumpla la integridad referencial entre dos tablas. Por ejemplo, entre la tabla de ventas de una librería y la tabla que recoge la información sobre los libros. Si en la relación entre ambas tablas exigimos integridad referencial siendo el campo de nexo el isbn, tendremos que dar de alta un libro con su isbn y demás datos antes de que se pueda usar ese isbn en la tabla de ventas. Esto tiene la ventaja de que nunca nos equivocaremos al decir que hemos vendido un libro con el isbn equivocado, ya que para que podamos vender un libro este tiene que estar previamente dado de alta en el inventario de libros .
Cuando exigimos integridad referencial entre dos tablas, al
establecer sus relaciones, estamos exigiendo a Access que no nos permita
introducir datos en un campo de la tabla secundario que no estuviera dado de
alta en la tabla primaria siempre que este sea el campo que la relaciona.
En el ejemplo de la base de datos de la librería, la tabla de libros es la tabla principal y el campo que une ambas tablas es el isbn. La tabla ventas es la tabla secundaria, y ambas se relacionan por una relación uno a varios. Al exigir integridad referencial no podremos vender un libro que previamente no estuviera dado de alta con su isbn correspondiente.
Es aconsejable marcar las tres casillas:
En el ejemplo de la base de datos de la librería, la tabla de libros es la tabla principal y el campo que une ambas tablas es el isbn. La tabla ventas es la tabla secundaria, y ambas se relacionan por una relación uno a varios. Al exigir integridad referencial no podremos vender un libro que previamente no estuviera dado de alta con su isbn correspondiente.
Es aconsejable marcar las tres casillas:
1. Exigir integridad referencial
2. Actualizar en cascada los campos relacionados
3. Eliminar en cascada los registros relacionados
Actualizar en cascada los campos relacionados hace que al cambiar el valor del campo de la tabla principal automáticamente cambien esos mismos valores en la tabla secundaria.
Ejemplo. Supongamos que tenemos una tabla con el Catálogo de libros relacionada con una tabla de Editoriales. Si una editorial cambia de nombre y la actualizamos en la tabla principal de Editoriales automáticamente cambiará en la tabla secundaria del Catálogo para todos los registros.
Eliminar en cascada los registros relacionados hace que al borrar un registro de la tabla principal automáticamente se borren todos los registros de la tabla secundaria que donde aparece ese datos.
Ejemplo. Supongamos que tenemos una tabla con el Catálogo de libros relacionada con una tabla de Editoriales. La tabla de Editoriales sería la tabla principal y la del Catálogo la secundaria. Si una editorial desaparece y eliminamos su registro en la tabla de Editoriales, automáticamente desaparecerán de nuestro Catálogo todos los libros que ofertaba esa editorial.
Si no marcamos ninguna de estas dos opciones no nos dejará cambiar el nombre de la editorial ni borrar ninguna editorial que ya este utilizada en la tabla secundaria del Catálogo.
1.5
RESTRICCIONES
Una
restricción es una condición que obliga el cumplimiento de ciertas condiciones
en la base de datos. Algunas no son determinadas por los usuarios, sino que son
inherentemente definidas por el simple hecho de que la base de datos sea
relacional. Algunas otras restricciones las puede definir el usuario, por ejemplo,
usar un campo con valores enteros entre 1 y 10.
Las
restricciones proveen un método de implementar reglas en la base de datos. Las
restricciones restringen los datos que pueden ser almacenados en las tablas.
Usualmente se definen usando expresiones que dan como resultado un valor
booleano, indicando si los datos satisfacen la restricción o no.
Las
restricciones no son parte formal del modelo relacional, pero son incluidas
porque juegan el rol de organizar mejor los datos. Las restricciones son muy discutidas
junto con los conceptos relacionales.
Dominios
Un
dominio describe un conjunto de posibles valores para cierto atributo. Como un
dominio restringe los valores del atributo, puede ser considerado como una
restricción. Matemáticamente, atribuir un dominio a un atributo significa
"todos los valores de este atributo deben de ser elementos del conjunto
especificado".
Distintos
tipos de dominios son: enteros, cadenas de texto, fecha,no procedurales etc.
Clave única
Cada
tabla puede tener uno o más campos cuyos valores identifican de forma única
cada registro de dicha tabla, es decir, no pueden existir dos o más registros
diferentes cuyos valores en dichos campos sean idénticos. Este conjunto de
campos se llama clave única.
Pueden
existir varias claves únicas en una determinada tabla, y a cada una de éstas
suele llamársele candidata a clave primaria.
Clave primaria
Una
clave primaria es una clave única elegida entre todas las candidatas que define
unívocamente a todos los demás atributos de la tabla, para especificar los
datos que serán relacionados con las demás tablas. La forma de hacer esto es
por medio de claves foráneas.
Sólo
puede existir una clave primaria por tabla y ningún campo de dicha clave puede
contener valores NULL.
Clave foránea
Una
clave foránea es una referencia a una clave en otra tabla. Las claves foráneas
no necesitan ser claves únicas en la tabla donde están y sí a donde están
referenciadas.
Por
ejemplo, el código de departamento puede ser una clave foránea en la tabla de
empleados, obviamente se permite que haya varios empleados en un mismo
departamento, pero existirá sólo un departamento.
1.6
SEGURIDAD DE BASE DE DATOS
Terminología
Seguridad: es el proceso de
controlar el acceso a los recursos; se basa en las credenciales y los permisos
del usuario de Windows.
Permisos: son reglas asociadas a
un recurso local o a un recurso compartido en una red, por ejemplo un archivo,
un directorio o una impresora. Los permisos se pueden conceder a grupos, a
grupos globales e incluso a usuarios individuales de Windows. Cuando se
conceden permisos de Windows, se especifica el nivel de acceso para grupos y
usuarios.
Seguridad del sistema
operativo o del sistema de archivos: comprueba los permisos cada vez que un usuario de Windows
interactúa con el recurso compartido, con el fin de determinar si dicho usuario
tiene los permisos necesarios. Por ejemplo, si ese usuario intenta guardar un
archivo en una carpeta, éste debe tener permisos de escritura en dicha carpeta.
Recursos compartidos: pone a disposición de
otros usuarios los recursos de Windows, como carpetas e impresoras. Los
permisos de recurso compartido restringen la disponibilidad de un recurso de
este tipo en la red sólo a determinados usuarios de Windows. El administrador
de una carpeta compartida concede permisos a los usuarios de Windows para
permitir el acceso remoto a la carpeta y a las subcarpetas. Compartir los
recursos de Windows es distinto a compartir archivos y proyectos en VSS.
Derechos: en VSS, especifican
los usuarios de esta aplicación que tienen acceso a un proyecto de VSS
concreto. Existen cuatro niveles de derechos de acceso de usuario en VSS: leer;
desproteger/proteger; agregar/cambiar nombre/eliminar y destruir. Se puede
especificar un nivel predeterminado para nuevos usuarios de la base de datos.
Asignaciones: en VSS, especifican
los proyectos de esta aplicación a los que tiene acceso un usuario determinado.
Carpeta de la base de
datos de VSS: es la carpeta de Windows que contiene el archivo Srcsafe.ini
de la base de datos, así como otras carpetas de VSS, por ejemplo Data y Users.
Proteger la base de datos y administrar los
usuarios
El programa del
Administrador de VSS proporciona herramientas para administrar los usuarios de
esta aplicación mediante la especificación de derechos de acceso para usuarios
o proyectos de VSS individuales en la base de datos de VSS. Sin embargo, si
desea proteger realmente la base de datos, debe utilizar la seguridad integrada
de Windows con el fin de restringir el acceso a las carpetas de VSS, mediante
el establecimiento de permisos de recurso compartido y de seguridad para estas
carpetas. Como se muestra en el siguiente diagrama, la protección de la base de
datos de VSS compartida es igual a la protección de la carpeta de red
compartida en la que se encuentra. Siga los procedimientos de bloqueo de la
base de datos para reforzar la seguridad de Windows, estableciendo o cambiando
los permisos de recurso compartido de la carpeta de la base de datos siempre
que cree una base de datos o agregue o elimine usuarios de VSS. De lo
contrario, cualquier usuario malintencionado de la red podrá evitar fácilmente
la pared transparente de derechos y asignaciones del usuario de VSS. No confíe
en VSS para proteger sus datos: hasta los usuarios de VSS con derechos de sólo
lectura pueden eliminar una base de datos de esta aplicación de una carpeta de
red compartida a la que tengan acceso.
Los
derechos y asignaciones del usuario de VSS que se establecen en el programa del
Administrador de VSS son independientes de los permisos de recurso compartido
de Windows para la carpeta de la base de datos de VSS. VSS utiliza el nombre de
usuario y la contraseña establecidos para esta aplicación a fin de administrar
los usuarios y el acceso a VSS. El nombre de usuario de VSS se utilizar para
administrar los derechos y asignaciones del usuario en el programa del
Administrador de VSS; dicho nombre identifica al usuario en el inicio de
sesión, en la información del historial y en los informes de archivos. Los
usuarios pueden iniciar una sesión en VSS utilizando el nombre de usuario y la
contraseña. VSS crea un archivo de inicialización (Ss.ini) y mantiene un
seguimiento del mismo para cada usuario de VSS; éste contiene valores para
personalizar el entorno de VSS de dicho usuario. Para proteger este archivo de
inicialización, siga las instrucciones de Bloquear la base de datos.
Para
obtener más información acerca de la seguridad de Windows, el control de acceso
y los permisos, vea la Ayuda de Windows.
Instrucciones para proteger la base de datos
Si
desea proteger la base de datos, debe utilizar la seguridad integrada de
Windows para restringir el acceso a las carpetas de VSS, de forma que sólo los
usuarios autorizados de Windows puedan obtener acceso a la base de datos o
ejecutar el programa del Administrador de VSS. La seguridad de la base de datos
de VSS está determinada por la seguridad de la carpeta que contiene dicha base
de datos. Si desea implementar la seguridad aquí descrita en la base de datos
de VSS, esta última debe estar instalada en un sistema de archivos de NT
(NTFS), ya que en NTFS se pueden conceder permisos para archivos y carpetas
individuales. El sistema de archivos de tabla de asignación de archivos (FAT)
aplica los mismos permisos a todo un recurso compartido.
Restringir permisos de recurso compartido
Cuando
se crea una base de datos compartida, se recomienda encarecidamente el uso del
Explorador de Windows con el fin de restringir los permisos de recurso
compartido de las carpetas de VSS. Debe eliminar el grupo Todos, que se agrega
automáticamente al compartir la carpeta de la base de datos de VSS. Se pueden
crear dos grupos de usuarios de Windows, administradores de VSS y usuarios de
VSS, y conceder a cada grupo los permisos adecuados para la carpeta de la base
de datos de VSS y para el resto de carpetas de esta aplicación. A cada usuario
de VSS también se le deben conceder permisos de lectura y escritura en la
carpeta Users/nombre usuario que se corresponda con el nombre de usuario de
éste en VSS. Para obtener instrucciones, vea Bloquear la base de datos.
Administrar usuarios
Al
agregar o eliminar usuarios de VSS, no sólo debe utilizar la lista de usuarios
del programa del Administrador de VSS para administrarlos; también deberá
agregar o eliminar sus permisos de recurso compartido de Windows. Para obtener
instrucciones, vea Bloquear la base de datos.
Consideraciones
adicionales
Instalar la base de datos en una ubicación segura
Durante
la instalación de VSS, se crea una base de datos de forma predeterminada en la
carpeta Data de VSS, ubicada bajo Archivos de programa. Esta base de datos está
concebida solamente para uso personal y no se debe compartir. Utilice la base
de datos de la ubicación predeterminada sólo si así lo requieren otros
programas.
Cualquier
usuario de Windows que tenga permisos de tipo Control total para las carpetas
de VSS puede reemplazar los archivos ejecutables de la carpeta Win32: siga los
procedimientos que se indican en Bloquear la base de datos para conceder
permisos de tipo Control total sólo a los usuarios del grupo del Administrador
de VSS. Asimismo, todos los usuarios de la base de datos de VSS necesitan
permisos para la carpeta de dicha base de datos; si esta carpeta se encuentra
bajo la carpeta Archivos de programa, contiene archivos ejecutables y recursos
relacionados.
No
cree una base de datos compartida en sus carpetas del sistema ni en las
carpetas Documents and Settings.
Ocultar el recurso compartido de VSS
Puede
ocultar el recurso compartido de red de forma que resulte muy difícil para los
usuarios de Windows remotos determinar si un servidor tiene un recurso
compartido y si VSS está instalado. El recurso compartido de red no aparece
cuando un usuario de Windows realiza búsquedas en el servidor. Si desea ocultar
el recurso compartido de red, agregue $ al final del nombre de la carpeta; por
ejemplo, en lugar de \\server\vssdb1 utilice \\server\vssdb1$. Deberá indicar a
sus usuarios de VSS la ubicación exacta de la base de datos, de forma que éstos
puedan agregarla a la lista Bases de datos disponibles del cuadro de diálogo
Abrir base de datos de SourceSafe.
Carpetas centrales
Al
crear una carpeta central para un proyecto de VSS, dicha carpeta no hereda los
permisos de usuario de Windows de las carpetas de VSS. Conceda permisos de
lectura y escritura en la carpeta central a todos los usuarios de VSS, y
conceda permisos de sólo lectura a los usuarios de Windows que requieran acceso
de sólo lectura a dicha carpeta. Para obtener más información, vea Crear
carpetas centrales.
Se
recomienda que cree una carpeta central en un recurso compartido distinto de la
base de datos de VSS, de forma que los usuarios de Windows con acceso de sólo
lectura a la carpeta central no tengan ningún permiso de acceso al recurso
compartido que contiene la base de datos. También se recomienda que cree una
carpeta central para un proyecto de VSS específico, y no para el proyecto raíz
$, de forma que los usuarios de Windows que tengan acceso a la carpeta central
sólo puedan obtener acceso a ese proyecto de VSS exclusivamente, no a la base
de datos completa.
Nota Al eliminar un archivo o un proyecto de un
proyecto de VSS, dicho archivo o proyecto no se eliminará en la carpeta
central.
Archivo
de diario
Si
crea un archivo de diario, se recomienda que proteja dicho archivo ubicándolo
en la misma carpeta que el archivo Srcsafe.ini y concediendo permisos de
lectura y escritura de Windows para el archivo de diario a los usuarios de VSS.
Para obtener más información, vea Crear archivo de diario.
Permisos
necesarios para instalar y ejecutar VSS
Para
poder instalar VSS en el equipo debe ser Administrador de Windows; sin embargo,
no se requieren permisos de administrador para ejecutar el programa del
Administrador de VSS o el Explorador de VSS y la línea de comandos.
Nombres de usuario Admin y Guest
Al
crear una base de datos de VSS se crean dos nombres de usuario de forma
predeterminada: Admin y Guest. Las contraseñas para el usuario Admin y el
usuario Guest están en blanco. Se recomienda que el usuario establezca una
contraseña para el usuario Admin utilizando el comando Cambiar contraseña del
programa del Administrador de VSS. Puede eliminar el usuario Guest o bien
establecer una contraseña para éste utilizando el comando Cambiar contraseña
del programa del Administrador de VSS. Para obtener información detallada, vea
Cambiar la contraseña de un usuario.
Contraseñas
Si
los usuarios de VSS tienen que escribir un nombre de usuario y una contraseña
para iniciar una sesión de VSS, indíqueles que no utilicen la misma contraseña
para el sistema operativo y para VSS. Si utilizan la misma y un pirata
informático descubre la contraseña de VSS, éste podrá utilizar la identidad del
usuario para obtener acceso al sistema operativo y a todos los programas.
Variables
de entorno SSUSER y SSPWD
Puede
establecer las variables de entorno SSUSER y SSPWD en el equipo para su nombre
de usuario y contraseña de VSS y así evitar que aparezca el cuadro de inicio de
sesión siempre que escriba un comando de VSS en la línea de comandos o inicie
el Explorador de VSS.
Si
establece dichas variables de entorno, cualquier usuario que utilice el equipo
podrá leer estas variables y ejecutar VSS utilizando su nombre de usuario y
contraseña.
Usar
el nombre de red para iniciar la sesión del usuario automáticamente
Visual
SourceSafe proporciona una opción Usar el nombre de red para iniciar la sesión
del usuario automáticamente que se puede utilizar para permitir la integración
de Visual SourceSafe con Microsoft Visual InterDev, Visual Studio .Net y
FrontPage. Para obtener información acerca de las consideraciones de seguridad
al utilizar esta opción, vea el artículo Q283618 de Microsoft Knowledge Base.
Usar
los derechos de proyecto de VSS
Si
desea especificar derechos de acceso para usuarios o proyectos de VSS
individuales, utilice los comandos Derechos por proyecto y Asignaciones de
derechos para usuario del menú Herramientas del programa del Administrador de
VSS. Para activar los comandos de menú, seleccione Activar comandos de derechos
y asignaciones en la ficha Derechos de proyecto del cuadro de diálogo Opciones
de SourceSafe.
Auditar
la actividad del usuario
Con
el programa del Administrador de VSS puede crear un archivo de diario: un
archivo de texto que registra cualquier acción realizada por un usuario de VSS,
que genera una entrada del historial para un archivo o proyecto en la base de
datos de VSS. Para obtener información detallada, vea General (Opciones de la
ficha, menú Herramientas) o Journal_File (Variable de inicialización). Los
administradores de Windows pueden auditar muchos eventos relacionados con la
seguridad, por ejemplo, el acceso a archivos y carpetas determinados. La
supervisión de este tipo de eventos puede ayudar a un Administrador de VSS a
detectar intentos de comprometer los datos de una base de datos de VSS. Para
obtener información acerca de la auditoría de eventos de seguridad y de acceso
a objetos como archivos o carpetas, vea la Ayuda de Windows.
1.7 REPORTES
DE BASE DE DATOS
● Los datos en una base de datos no son
usualmente consultados a través de las tablas. Para ello se crean consultas y
reportes.
● Las consultas son vínculos de datos en
distintas tablas generados una vez.
● Reportes son aquellas consultas que se
guardan como una plantilla para ser procesadas frecuentemente. Los reportes
además usualmente incluyen procesamiento de los datos.

Un gestor de base de
datos (DataBase Managenent System) es un sistema que permite la creación,
gestión y administración de bases de datos, así como la elección y manejo de
las estructuras necesarias para el almacenamiento y búsqueda de la información
del modo más eficiente posible.

1.8.1 BAJO LICENCIA
Microsoft SQL Server
Es un sistema de gestión de bases de
datos relacionales basado en el lenguaje Transact-SQL, capaz de poner a disposición
de muchos usuarios grandes cantidades de datos de manera simultánea.
Es un sistema propietario de
Microsoft. Sus principales características son:
§ Soporte de
transacciones.
§ Escalabilidad,
estabilidad y seguridad.
§ Soporta
procedimientos almacenados.
§ Incluye también un
potente entorno gráfico de administración, que permite el uso de comandos DDL y
DML gráficamente.
§ Permite trabajar en
modo cliente-servidor donde la información y datos se alojan en el servidor y
las terminales o clientes de la red sólo acceden a la información.
§ Además permite
administrar información de otros servidores de datos
Su principal desventaja es el precio,
aunque cuenta con una versión EXPRESS que permite usarlo en entornos
pequeños. (Aprox. unos 4GB de información y varios millones de registros por
tabla)
Oracle
Es un sistema de gestión de base de
datos relacional (o RDBMS por el acrónimo en inglés de Relational Data Base
Management System), fabricado por Oracle Corporation.
Tradicionamente Oracle ha sido el SGBS
por excelencia, considerado siempre como el más completo y robusto, destacando
por:
§ Soporte de
transacciones.
§ Estabilidad.
§ Escalabilidad.
§ Es multiplataforma.
Tambien siempre ha sido considerado de
los más caros, por lo que no se ha estadarizado su uso como otras aplicaciones.
Al igual que SQL Server, Oracle cuenta
con una versión EXPRESS gratis para pequeñas instalaciones o usuarios
personales.
Bajo licencia Microsoft Access
Es un sistema de gestión de bases de
datos Relacional creado por Microsoft (DBMS) para uso personal de pequeñas
organizaciones.
Se ha ofrecido siempre como un
componente de la suite Microsoft Office aunque no se incluye en el paquete
“básico”.
Una posibilidad adicional es la de
crear ficheros con bases de datos que pueden ser consultados por otros
programas.
Entre las principales funcionalidades
reseñables podemos indicar que:
§ Permite crear tablas
de datos indexadas.
§ Modificar tablas de
datos.
§ Relaciones entre
tablas (creación de bases de datos relacionales).
§ Creación de consultas
y vistas.
§ Consultas referencias
cruzadas.
§ Consultas de acción
(INSERT, DELETE, UPDATE).
§ Formularios.
§ Informes.
§ Entorno de
programación a través de VBA
§ Llamadas a la API de
windows.
1.8.2 LIBRE
MySQL
Es un sistema de gestión de base de
datos relacional, multihilo y multiusuario seguramente el más usado en
aplicaciones creadas como software libre.
Por un lado se ofrece bajo la GNU
GPL, pero, empresas que quieran incorporarlo en productos privativos pueden
comprar a la empresa una licencia que les permita ese uso.
Ventajas:
§ Velocidad al realizar
las operaciones
§ Bajo costo en
requerimientos para la elaboración de bases de datos
§ Facilidad de
configuración e instalación.
Libre DB2
Este SGBD es propiedad de IBM,
bajo la cual se comercializa el sistema de gestión de base de datos. Utiliza
XML como motor, además el modelo que utiliza es el jerárquico en lugar del
modelo relacional que utilizan otros gestores de bases de datos. Es el único de
los gestores que hemos comentado que nos relacional.
Sus características más importantes
son:
§ Permite el manejo de
objetos grandes (hasta 2 GB)
§ La definición de
datos y funciones por parte del usuario, el chequeo de integridad referencial,
§ SQL recursivo,
soporte multimedia: texto, imágenes, video, audio; queries paralelos, commit de
dos fases, backup/recuperación on−line y offline.
§ Permite agilizar el
tiempo de respuestas de esta consulta
§ Recuperación
utilizando accesos de sólo índices.
§ Predicados
correlacionados.
§ Tablas de resumen
§ Tablas replicadas
§ Uniones hash
Su principal
desventaja es el precio, está dirigido solo a grandes empresas con necesidades
de almacenamiento y procesamiento muy altas.
Al igual que SQL Server y Oracle
dispone de una versión EXPRESS gratis pero no de libre distribución.
Existen muchos más gestores de bases
de datos en el mercado, pero estos como he comentado son los más
usados.
Todos son relacionales (a excepción
del BD2) y comparten por tanto lenguaje de consulta (con algunas
variantes propias) que es SQL. Es importante por tanto para cualquiera que
desee trabajar con bases de datos comenzar por el estudio de este lenguaje
común y luego estudiar las peculiaridades de la base de datos en cuestion.
Entre los citados seguro que
encontramos el que más se adapta a nuestras necesidades de acuerdo a inversión
a realizar, volumen de información a almacenar, tipo de consultas a realizar, etc.
Al revisar la unidad 1 pude percatarme de que no se estableció un mismo formato para el texto
ResponderEliminarMás imágenes hubieran complementado mejor esta unidad.
ResponderEliminarMuy bien chicos es buen trabajo sólo que le falto detalles..Pero gracias por el esfuerzo
ResponderEliminarBuen día en esta unidad uno aprendí a realizar las relaciones en excel donde donde teníamos que ver que campos coincidían para poder realizarla,también el uso de los softwares empresariales de Aspel, así como las presentaciones que hicimos en emazi, prezi y powtoon.
ResponderEliminarEste comentario ha sido eliminado por el autor.
ResponderEliminarHola buen día jóvenes!!!, la información esta bien, así como el tamaño y tipo de fuente.solo algunos párrafos necesitan revisar el formato y justificar, revisen la alineación de las imágenes en esta unidad y por favor poner el mismo color de fuente para los títulos y subtitulos Gracias por colaborar
ResponderEliminarHola buen día.
ResponderEliminarLas bases de datos juegan un papel muy importante en la mayoría de las áreas donde se utiliza un computador, por eso debemos tener en claro la función de esta poderosa aplicación. El aprendizaje que me llevo de esta unidad es la realización de relaciones de Entidad-Relación en el programa de Access, al igual que a identificar los pasos de la normalizacion de base de datos.
Buen día!!
ResponderEliminarEn este unidad aprendí que los modelos de base de datos mas que nada nos sirve para guardar información y eso nos ayuda demasiado y ay diferentes modelos Bases de datos red, jerárquicas, transaccionales y relacionales también aprendimos sobre la normalizacion en access.
Buenos dias a todos!
ResponderEliminarEn esta primera unidad aprendi a identificar los diferentes modelos de base de datos, asi como los pasos a seguir para la normalizacion al crear páginas web
Hola buenas noches esta unidad fue la que investigue con mi compañera diana espero y sea de su agrado.
ResponderEliminarEn esta unidad aprendí que existen diferentes modelos de bases de datos que nos ayudan a guardar información importante para nuestro uso en cualquier momento que nosotros lo necesitemos.
Hola jóvenes buen día, agradezco que hayan colaborado y mejorado esta entrada U1; muy bien
ResponderEliminarEs una experiencia para mi adquirí los conocimientos necesarios acerca de los difieres tipos de modelo base de datos en conocer su función el manejo y la practicas de las actividades llevada a cabo.
ResponderEliminar